工具介绍
Robots.txt 在线生成器是一款功能强大的工具,专为网站管理员、SEO优化人员和网站开发者设计。它能够快速生成符合标准的robots.txt文件,帮助网站控制各种爬虫的访问行为,包括传统搜索引擎、AI爬虫和SEO分析工具。
本工具支持国内外主流搜索引擎的精细控制,可设置Sitemap地址、爬取间隔,以及针对不同类型爬虫的访问规则。通过直观的界面,用户可以轻松配置复杂的robots.txt规则,优化网站的SEO策略,提高搜索引擎抓取效率,同时保护网站敏感内容。
工具界面展示
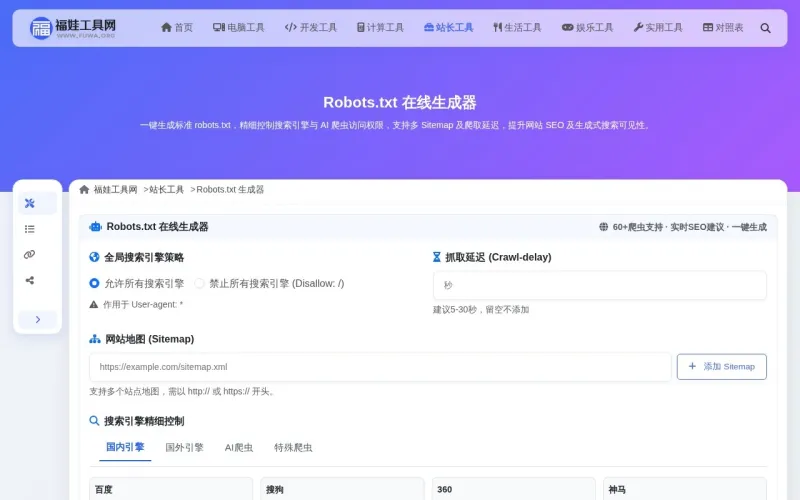
功能特色
- 多爬虫类型支持:支持传统搜索引擎、AI爬虫、SEO分析工具等60+爬虫
- 精细控制:可对每个爬虫单独设置抓取规则,分类管理
- 路径规则管理:支持添加多条Allow/Disallow规则,可自由调整顺序
- 自动注释生成:根据User-agent和指令自动生成注释,提高规则可读性
- Sitemap配置:可添加多个Sitemap地址,帮助搜索引擎发现网站内容
- 爬取间隔设置:可设置Crawl-delay,控制搜索引擎抓取频率
- 实时预览:修改规则后实时生成robots.txt预览
- SEO实时建议:根据配置提供实时SEO优化建议
- 预设UA下拉菜单:提供常用爬虫的预设选项,快速选择
- 一键复制:生成的robots.txt内容可一键复制到剪贴板
- 文件下载:可直接下载生成的robots.txt文件
- 文件导入:支持导入现有robots.txt文件进行编辑
使用方法
- 设置全局策略:选择允许或禁止所有搜索引擎抓取
- 添加路径规则:点击"添加规则"按钮,设置User-agent、指令和路径,系统会自动生成注释
- 配置爬虫:在精细化控制面板中为特定爬虫设置规则,包括传统搜索引擎、AI爬虫和SEO分析工具
- 添加Sitemap:在Sitemap输入框中输入Sitemap地址,点击"添加 Sitemap"按钮
- 设置爬取间隔:在Crawl-delay输入框中设置爬取间隔时间
- 查看实时预览:所有配置变更会自动更新robots.txt预览
- 参考SEO建议:查看系统提供的实时SEO优化建议
- 复制或下载:使用"复制"按钮复制内容,或"下载"按钮下载文件
适合人群
- 网站管理员:需要管理网站爬虫访问权限的网站管理员
- SEO优化人员:需要优化网站SEO策略的专业人员
- 网站开发者:开发网站并需要配置robots.txt的开发者
- 数字营销人员:需要控制爬虫行为以优化营销效果的营销人员
- 内容创作者:需要保护原创内容的内容创作者
常见问题解答(FAQ)
什么是robots.txt文件?
robots.txt是一个位于网站根目录的文本文件,用于告诉搜索引擎爬虫哪些页面可以抓取,哪些页面不应该抓取。它是网站与搜索引擎之间的一种协议。
为什么需要robots.txt文件?
robots.txt文件可以帮助您控制搜索引擎爬虫的行为,避免爬虫抓取敏感内容,减少服务器负担,提高抓取效率,优化SEO策略。
如何使用本工具生成robots.txt文件?
设置全局策略,添加路径规则,配置爬虫,添加Sitemap,设置爬取间隔,查看实时预览和SEO建议,复制或下载生成的robots.txt文件。
本工具支持哪些爬虫?
支持传统搜索引擎、AI爬虫、SEO分析工具等60+爬虫,包括Google、百度、Bing、OpenAI GPTBot等。
生成的robots.txt文件如何使用?
将生成的robots.txt文件上传到网站的根目录下,确保文件名为robots.txt,并且位于网站的根路径(如https://www.fuwa.org/robots.txt)。
本工具是否支持导入现有robots.txt文件?
是的,本工具支持导入现有robots.txt文件进行编辑,您可以点击预览区域的'导入'按钮,选择本地的robots.txt文件进行导入。
为什么要控制 AI 爬虫?
控制 AI 爬虫可以保护网站的原创内容不被未经授权的 AI 模型训练使用,减少服务器负担,避免敏感信息被 AI 抓取,同时可以确保网站资源被合理使用,不会被 AI 爬虫过度消耗。
什么是User-agent?
User-agent是搜索引擎爬虫的标识符,用于区分不同的搜索引擎。例如,Google的爬虫标识符是Googlebot,百度的是Baiduspider。
Allow和Disallow指令有什么区别?
Allow指令告诉爬虫可以抓取指定路径,Disallow指令告诉爬虫不应该抓取指定路径。
什么是Sitemap?
Sitemap是一个XML文件,用于告诉搜索引擎网站上有哪些页面可供抓取。在robots.txt中添加Sitemap地址可以帮助搜索引擎更有效地发现网站内容。
Crawl-delay是什么?
Crawl-delay是一个指令,用于告诉搜索引擎爬虫两次请求之间应该等待的秒数。这可以帮助减少服务器负担。
robots.txt文件会被搜索引擎立即识别吗?
搜索引擎需要时间来发现和处理robots.txt文件的更改,通常需要几天时间才能完全生效。
robots.txt可以阻止所有爬虫吗?
虽然robots.txt可以告诉爬虫不要抓取某些内容,但恶意爬虫可能会忽略这些指令。对于敏感内容,建议使用其他安全措施。
如何测试robots.txt文件?
您可以使用Google Search Console的robots.txt测试工具来验证您的robots.txt文件是否正确配置。
更新日期: